Don't settle for half the story
Demyst gives you access to all of the data you need. Evaluate thousands of data attributes from hundreds of possible data connectors all pulled into your own custom-built APIs for instant data deployment.


The Demyst Team

As stimulus monies flow across the globe to keep businesses afloat and staff employed, governments and financial institutions have been escalating concerns about synthetic fraud. In a series of recent listening sessions with the US Office of the Comptroller of Currency (OCC), a number of banks raised the issue of synthetic fraud in the US Paycheck Protection Program directly and the challenges faced in detecting and preventing it (1).
We know that most banks and lenders are trying to solve this, and most now use a growing number of 3rd party software platforms. However, the successful organisations are those who are dynamically testing and deploying combinations of external data with these existing platforms. We recently worked with a global bank who had a synthetic fraud problem in their credit card product which was able to be cut by 17% in 6 weeks, without having to rely on internal IT teams or scale up their resourcing. Understanding how to leverage additional data combined with automated feature creation and dynamic machine learning we believe, is the key to regaining the advantage in the battle against fraud.
What is Synthetic Fraud?
Synthetic fraud has typically been associated with the generation of a legitimate-looking identity through the use of a combination of real and fictitious information (such as a valid SSN combined with a fake name). However, the impact of and response to CoVID19 has seen organised crime groups extend this type of fraud further by creating synthetic businesses with the intent of exploiting business support programs as well.

How does Synthetic Fraud Work?
Synthetic identities, whether individual or corporate, are predominantly used for two (2) purposes:
However, the rollout of emergency small business loans across the globe is now highlighting the emergence and impact of synthetic business fraud (2). As organisations double down on their KYC processes for individuals, Know Your Business (KYB) processes are proving more difficult. Participants in the OCC listening sessions (1) identified one of the main difficulties with synthetic business fraud at present was simply being able to identify and assess whether a business was actually open. Digging deeper into a business’s registration status, ownership structure and parties, and determining the no. of employees increasingly takes time and added to the complexity of business fraud detection.
What does it take to address Synthetic Fraud?
Internal data alone provides limited capability to prevent, detect and respond to synthetic fraud. Banks and lenders need to do more than collect and verify PII. They need broad and reliable information upon which they can rapidly assess a customer’s ‘Pattern of Life’ and ‘Activity within the Community’. We’ve verified who this customer claims to be using the limited information they’ve provided but how do we establish real-world behaviour, attributes and activity to support this?
How can I rapidly and reliably confirm the bona fide existence and operation of a business, albeit as a customer or an individual’s nominated employer?
Measuring a customer’s “real life” data footprint and comparing it across a variety of external data sources for correspondence establishes to a reasonable degree of certainty that the individual or business lives and breathes in the real world. Even during lockdown, we all continue to have real-world engagement, although a lot more is now performed digitally (think home delivery for groceries & other essentials, fast food, entertainment, clothing, flowers, gifts and other purchases, etc).
With 600+ data sources and in excess of 100,000 attributes, Demyst provides unrivalled and rapid access to external data.

2. Automated feature creation:
By accessing an abundance of reliable external data, solving complex organisational problems can be simplified through first principles, avoiding assumptions and testing hypotheses. However, meeting customer expectations and solving complex fraud problems at scale have a common denominator — time. Building risk models is often a painstaking and tedious process that typically involves many steps, in particular feature creation/engineering. Combining internal data with dynamic and varied external data with automated feature creation has the effect of exponentially improving the performance and reliability of fraud predictive models. Benefits of automated feature creation include:
3. AutoML
Dynamic problems need dynamic solutions. We all know that customer experience is directly tied to the time it takes to reach a decision — take too long and customers ‘vote with their feet’. As organisations adopt new technology to meet customer demands, organised criminals rapidly adapt to meet or exploit those changes. Changes to behaviour and corrections on controls lead to changes in the multivariate predictors of what represents anomalous behaviour. AutoML fuelled with external data is perfectly suited to this problem.
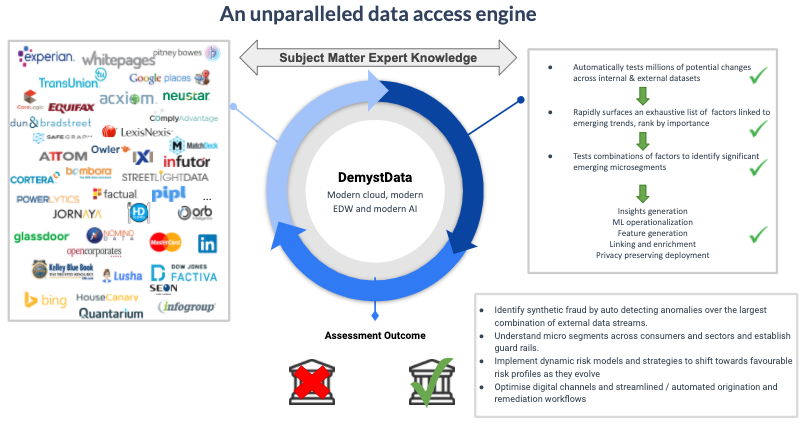
DemystData is an unparalleled data access engine that can test millions of potential changes across internal and external datasets; rapidly surface an exhaustive list of factors linked to emerging trends, rank by importance; and test combinations of factors to identify significant emerging micro-segments and anomalies.
Identifying synthetic fraud (individuals or businesses) does not need to be an arduous and time-consuming task. It does, however, require an appetite to increase external data usage to uplift detection models. Like the bank that reduced fraud within 6 weeks, organisations that similarly adopt a dynamic and varied external data strategy will reduce their exposure to synthetic and other types of fraud.
Don't settle for half the story
Demyst gives you access to all of the data you need. Evaluate thousands of data attributes from hundreds of possible data connectors all pulled into your own custom-built APIs for instant data deployment.
External data can be easy to discover and deploy