Authorization — Using API keys and generating tokens
Authentication
The Demyst API supports three secure, industry-standard methods of authorization so that organizations can choose the best fit for their preferred information security policies.
API Keys
Users can generate, control, and destroy REST API keys through the Demyst platform to conform with their organization's rotation policies. Demyst will not store API keys in plain text, which means that keys must be saved when they are generated.
Sample cURL request with token generation:
https://gw.us.demystdata.com/v2/channel
 curl
curl
curl -X POST \
https://gw.us.demystdata.com/v2/channel \
-H 'Content-Type: application/json' \
-d '{
"api_key": "xxxxxxxxxxxxxxxxxxxxxx",
"id": 1020,
"inputs": {
}
}'
JWT
JSON Web Tokens can be used in compliance with the industry-standard RFC 7519 method.
Tokens can be generated with the email address (username) and password of an account that has provisioned access to the Demyst platform.
Passwords expire after 90 days, and tokens are valid for 24 hours.
Sample cURL request with token generation:
https://console.demystdata.com/jwt/create
curl
curl -X POST \
https://console.demystdata.com/jwt/create \
-H 'Content-Type: application/json' \
-d '{
"email_address": "EMAIL",
"password": "PASS"
}'
#Use the response token from above in below
curl -X POST \
https://gw.us.demystdata.com/v2/channel \
-H 'Content-Type: application/json' \
-d '{
"api_key": "JWT_FROM_ABOVE",
"id": 1020,
"inputs": {
}
}'
OAuth 2.0
Demyst supports OAuth 2.0 protocol for Authorization. You could obtain access to our Data API services, as a resource owner by orchestrating an approval interaction between the resource owner and our services.
-
Demyst supports resource owner credentials OAuth 2.0 grant (RFC 6749, §4.3) and a refresh token OAuth 2.0 grant (RFC 6749, §1.5, §5). These grant types provide different options for authentication and authorization in the OAuth 2.0 framework, offering flexibility in different application scenarios.
-
Resource Owner Credentials Grant (RFC 6749, §4.3):
- This grant type allows Clients to obtain an access token by presenting the resource owner's (end user's) credentials, i.e. username and password, directly to our authorization server.
- The Client application collects the user's credentials and includes them in the token request to our authorization server.
- Client ID and Client Secret are typically used for Client authentication, while the username and password are used for resource owner authentication (also known as the "password grant type").
-
Refresh Token Grant (RFC 6749, §1.5, §5):
- The refresh token grant type allows Clients to obtain a new access token without requiring the resource owner to re-authenticate.
- After the initial authentication and token issuance, the Client receives both an access token and a refresh token.
- When the access token expires, the Client can use the refresh token to request a new access token from the authorization server.
- This is useful to obtain long-lived access to resources without requiring the user to provide their credentials again.
Requests
Step 1 - Generating Access token and Refresh token
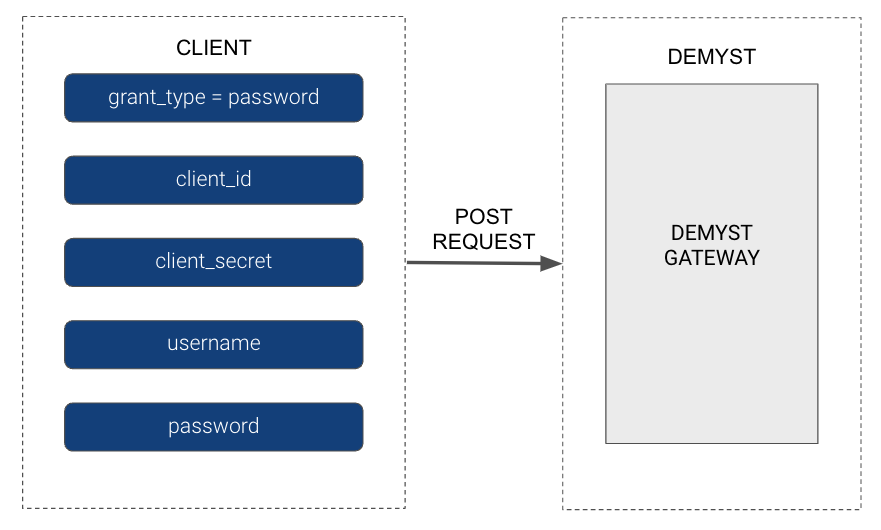
The Client sends a POST request to generate a token:
curl -X POST \
https://gw.us.demystdata.com/oauth/token \
-d 'grant_type=password&client_id=DEMYST_GENERATED_ID& \
client_secret=DEMYST_GENERATED_SECRET& \
username=CLIENT_PROVIDED_USER& \
password=CLIENT_PROVIDED_PASS'
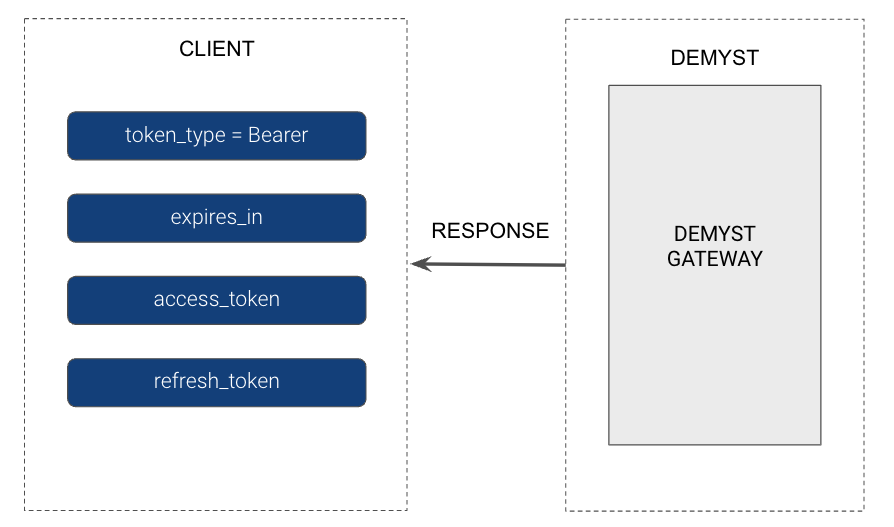
Demyst will issue an Access token (API Key) with a TTL of 10 minutes, as well as a Refresh token:
# Sample Response
{
"token_type": "Bearer",
"access_token": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"expires_at": "2022-11-17T15:29:38.721873Z",
"refresh_token": "xxxxxxxx"
}
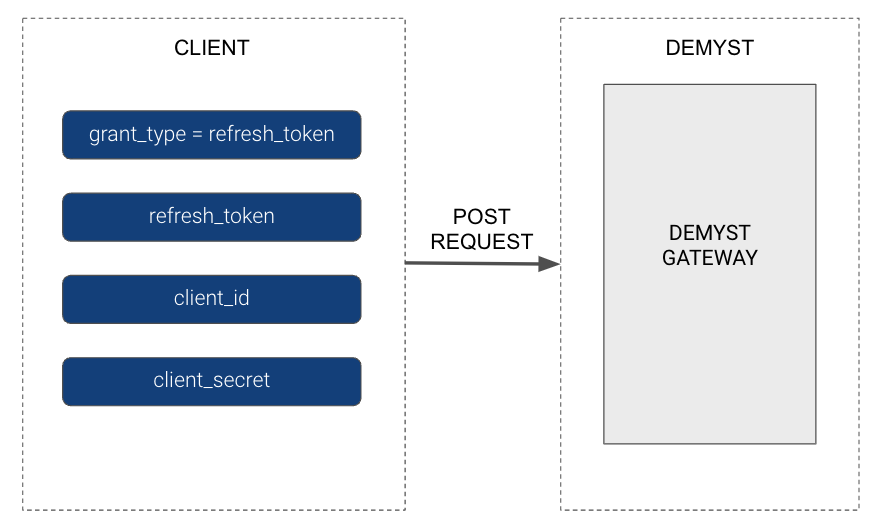
Step 2 - Generating Access token using Refresh token
The Client sends a POST request containing a Refresh token from the above steps:
# Generate access_token using refresh_token
curl -X POST \
https://gw.us.demystdata.com/oauth/token \
-d 'grant_type=refresh_token&client_id=DEMYST_GENERATED_ID& \
client_secret=DEMYST_GENERATED_SECRET& \
refresh_token=REFRESH_TOKEN_FROM_ABOVE'
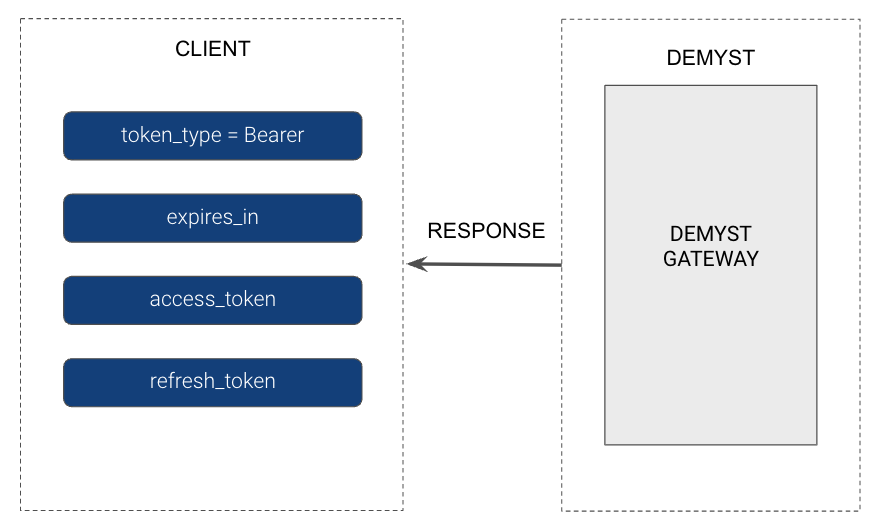
Demyst will return the Access token (API Key) + Refresh token as specified above:
# Sample Response
{
"token_type": "Bearer",
"access_token": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"expires_at": "2022-11-17T15:39:38.721873Z",
"refresh_token": "xxxxxxxx"
}
Step 3 - Use the Access token to get data
In the last step, you will provide the Access token as the API Key in the request with your channel/Data API to get the data.
curl -X POST \
https://gw.us.demystdata.com/v2/channel \
-H 'Content-Type: application/json' \
-d '{
"api_key": "ACCESS_TOKEN_FROM_ABOVE",
"id": 1020,
"inputs": {
}
}'
Errors
Here are some common errors you might see when setting up the OAuth in your application.
-
Invalid token - If you supply an incorrect token to the API Key in the call to get the data, you will receive an HTTP error code of 403 with the below error:
{ "transaction_id": "694c9505-43bf-46cb-94d1-09f5a3b41b4c", "error": { "type": "unable_to_verify_jwt_token", "message": "We could not verify the api token." } } -
Token expiration - Sending an expired token will also result in an HTTP error code of 403 with the below error. The TTL for the Access token is 10 minutes:
{ "transaction_id": "7047ad96-150b-47c7-8baf-0c304cc47491", "error": { "type": "jwt_token_expired", "message": "The api token is expired." } } -
Channel access denied - The Oauth is set for a particular channel/Data API. If the channel is not enabled for OAuth and you try to use the authentication on it, you will get an HTTP error code of 403 with the below error message:
{ "transaction_id": "5696aadd-ce83-4397-a8f6-845d50c1f202", "error": { "type": "channel_access_denied", "message": "API key has no access to channel 366" } }
Setup for Clients
OAuth setup will take 5-10 business days depending on the availability of the input request items.
-
Resource owner's credentials - The end user's username and password should be secretly shared with Demyst to set up OAuth. Demyst recommends sharing two sets, one for evaluation (testing and UAT) and another for production.
-
Channel ID/Data API - The Client will need to share the Data API/Channel IDs for which they want OAuth authorization to be enabled. Only channels added by Demyst will work with OAuth authorization, otherwise a channel access denied error message will be returned.
Once the details are sent to the Platform Engineering team, they will provide the Client with a Client ID and Client secret on completion of the request. If two sets of user credentials were provided, Demyst will also provide two sets of Client credentials for the two different environments and usage. If needed, Demyst can add more channels/Data APIs for the OAuth Authorization at a later time that will use the same sets of user and Client credentials.
Sample Request and Response
Demyst API configurations are saved within the platform.
A user that creates a data API from a recipe or a data product gains access to the single lookup interface, the configuration edit interface, metrics and tracking screens, and programmatic access to the Data API.
An API request to a channel returns the same response that appears in the single lookup results view on the platform.
This part of the documentation shows how to create API requests and how to make sense of the output.
Request Details
URL and Request Type
The Demyst API is accessed at https://gw.CC.demystdata.com/v2/channel, with CC replaced by the region in which your execution servers are running (us, au, eu, sg). Requests to the API should be sent as HTTPS POST requests.
Authentication
Requests require an API Key for authentication. View more details on API Keys here.
Channel ID
The "id" is the Channel ID number from your saved data API on the Demyst platform. This is shown at Data APIs > Your Data API > Settings. The Channel ID sends inputs to that specific configuration so that the correct data is appended.
Inputs
The inputs use the same information that would be used on the single lookup page. Use the exact same keys that appear on that screen (in the example above, "country", "state", "city", "street", "post_code", "first_name", "last_name").
Connection
All requests to Demyst are made over secure TLS 1.2 channels using HTTPS. The host you communicate with depends on the region that you are working with.
Sample Request
https://gw.us.demystdata.com/v2/channel
curl
curl -X POST \
https://gw.us.demystdata.com/v2/channel \
-H 'Content-Type: application/json' \
-d '{
"api_key": "xxxxxxxxxxxxxxxxxxxxxx",
"id": 1020,
"inputs": {
"country": "US",
"state": "NY",
"city": "New York",
"street": "100 Main Street",
"post_code": "10001",
"first_name": "JOHN",
"last_name": "DOE"
}
}'
Response Details
Transaction ID
The transaction_id is a unique value that references the API transaction. This reference ID can be used to communicate with Demyst about the transaction without sharing any sensitive data.
Refine
The "refine" section of the response displays the attributes that are defined in the refine section of the saved configuration. These attributes use the raw response data from providers to derive new attributes, or simply rename and highlight them.
The full response from the providers can include hundreds of attributes and complex structuring. The "refine" section gives users a way to customize a Data API by sectioning off the important, cleaned data. For more details on how to define refine attributes, see our Data APIs page.
Channel ID
The full response from the providers can include hundreds of attributes and complex structuring. The "refine" section gives users a way to customize a Data API by sectioning off the important, cleaned data. For more details on how to define refine attributes, see our title--small page.
Refine Errors
Because the refine configuration is freely written by users, errors will occur — especially in the development phase. The "refine_errors" section provides feedback on specific attributes when an error occurs.
Output
The "output" is a container for subsections from each provider that was run. In the example above, only "hazardhub_risks_and_enhanced_property2" was run.
Data
The "data" section is Demyst's parsing of the raw response from the data provider. The example only provides three data points, but data providers can return hundreds. Demyst preserves as much of the original response's structure as possible. In this case, the "enhanced_property" and "assessment" sections are included in Demyst's presentation of the data.
Flattened Data (optional)
This section takes everything in "data" and presents it as a single level of key-value pairs. It allows the data to be entered as a single row in a table, showing which subsection contains the data point by looking for the key name. This section is not included in responses by default. To receive this section, the "config" section of the configuration must include the setting: "return_flattened_data":true . See the config page for more details.
Raw Data (optional)
The "raw_data" section returns the data exactly as Demyst receives it from the data provider, in the spirit of full transparency. This section is not included in responses by default. To receive this section, the "config" section of the configuration must include the setting: "return_raw_data":true . See the config page for more details.
Cached
This shows whether the response was fetched live or fetched from the cache. A response will only be fetched from the cache if the request is made in cache mode and an identical request has been made recently. See more about cache mode and Demyst's caching in the mode section.
Response Time
This value is the time Demyst needed to fetch the data from the provider. It is collected and displayed in a more usable way on the Data API's dashboard, but it can also be collected and analyzed through this field in the API response.
Version
This value is a simple reference to the version of the data product used in the request.
Data providers occasionally add or remove data from their responses, or they allow new inputs to be queried. Whenever Demyst updates its connection with a data provider, a new version is created.
By default, Demyst uses the latest implementation and version of all data products. However, a static version is often configured for production purposes, which means that unexpected schema changes can occur.
Pipes
This is a legacy section. In most cases, it can safely be ignored.
Sample Response
https://gw.us.demystdata.com/v2/channel
json
{
"transaction_id" : "291ada41-d4e4-42c2-8696-25d9c8041b9e",
"refine" : {
"approve_applicant":true,
"applicant_segment":"B",
},
"refine_errors" : {
},
"output" : {
"hazardhub_risks_and_enhanced_property2" : {
"data" : {
"enhanced_property": {
"assessment": {
"assessed_improvement_value": 206160,
"assessed_land_value": 39360,
"assessment_year": "2021"
}
}
},
"cached" : true,
"response_time" : 363,
"raw_data": {
"body": "{\"enhanced_property\":{\"assessment\":{\"Assessed_Improvement_Value\":206160,\"Assessed_Land_Value\":39360,\"Assessment_Year\":\"2021\"}}}"
"mime_type": "application/json; charset=utf-8"
},
"flattened_data" : {
"enhanced_property.assessment.assessed_improvement_value": 206160,
"enhanced_property.assessment.assessed_land_value": 39360,
"enhanced_property.assessment.assessment_year": "2021"
},
"version" : 8
},
},
"pipes" : {
}
}
Demyst Types
Demyst validates all received inputs before sending to provider.
Required formats are as follows:
| Data Type | Description | Base Type | Example |
|---|---|---|---|
| abn | 11-digit Australian Business Number | Number | 11 223 344 556 or 1122344556 |
| address | A full address with enough location identifiers to parse a valid address. With or without country | String | 28 W 25th St. Floor 9 10010 |
| blob | Base64-encoded binary data | String | RGVteXN0 |
| boolean | True/False indicator. Generic, free-form type | Boolean or String | true, False, y, N, 0, 1, .. |
| business_name | The name of a company | String | Demyst Data Ltd. |
| city | The name of a city | String | New York City |
| country | Must be a 2 or 3 character iso code https://en.wikipedia.org/wiki/ISO_3166-1_alpha-3 or https://en.wikipedia.org/wiki/ISO_3166-1_alpha-2 | String | US, AU, SG |
| date | 8-digit date with format CCYY-MM-DD | ISO 8601 | 2016-12-31 |
| date_of_birth | 8-digit (CCYY-MM-DD), 6-digit (CCYY-MM) or 4-digit (CCYY) date of birth | ISO 8601 | 2016-12-31, 2016-12, 2016 |
| date_time | Full timestamp or 8-digit (CCYY-MM-DD) date | ISO 8601 | 2016-12-31T06:21:40Z or 2016-12-31 |
| domain | An internet domain name | String | demyst.com |
| email_address | An email address | String | support@demyst.com |
| first_name | A first name | String | John |
| full_name | A full name | String | John Rupert Doe |
| gender | A gender or abbreviation | String | m, male, f, female |
| ip4 | IP address, version 4 (32-bit address). Must contain 4 octets between 0 and 255, and 3 periods | Numbers | 192.168.0.1 |
| ip6 | IP address, version 6 (128-bit hexadecimal address). Must have 8 segments between 0 and FFFF, and 7 colons | String | 3ffe:1900:fe21:4545:0000:0000:0000:0000 |
| last_name | A last name | String | Smith |
| latitude | Number between -90.0–90.0 | Number | 40.7 |
| longitude | Number between -180.0–180.0 | Number | -73.9 |
| marital_status | A marital status or abbreviation | String | m, married, s, single, ... |
| middle_name | A middle name | String | Rupert |
| month_day | A day of a month.4-digits with format MM-DD | ISO 8601:2000 | 12-31 |
| naics_code | A North American Industry Classification System code. 5 or 6-digit numeric industry code | Number | 011100 |
| number | Positive or negative number. Supports integral and decimal numbers of arbitrary size and precision. Generic, free-form type | Number | -42, 0.5, 2.0000057301 |
| percentage | A number between -100.0 and 100.0 (negative numbers would imply a percent difference) | Number | 99%, 99 |
| phone | Country dependent. For US: must be 10 numeric digits without leading "1" or 11 digits with, and area code must be valid. Dashes stripped during validation | Number | 917-475-1881 |
| post_code | If US: 5 or 9 digit postal code, dash or no dash separating. Other countries need be non-empty. Certain countries must be alphanumeric | String | 10001 |
| post_code_extension | 4-digit (or less) postal code extension | Number | 4863 |
| sic_code | A Standard Industrial Classification code. 4-digit numerical industry code | Number | 2024 |
| state | If US: it must be a valid 2 character state code or state name. Empty otherwise | Number | NY, New York |
| street | Non-empty. A street name | String | 100 Main St |
| string | A character string. Generic, free-form type | String | foo |
| updated_at | Full timestamp or 8-digit date for when the object was last updated | ISO 8601 | 2016-12-31T06:21:40Z or 2016-12-31 |
| url | A Uniform Resource Locator. Starts with http: or https: | String | https://demyst.com/console/documentation/knowledge_base/third_party_catalog_integration#archivedLookups |
| us_ein | (Only US) An Employer Identification Number. Dashes and spaces stripped from input by us, must be 9 numeric character string | Number | 12-3456789 |
| us_ssn | (Only US) A Social Security Number. Dashes and spaces stripped from input by us, must be 9 numeric character string | Number | 078-05-1120 |
| us_ssn4 | (Only US) The last four digits of a Social Security Number | String | 1120 |
| vin | 17-digit alphanumeric Vehicle Identification Number | String | 1Z2YX34567W890123 |
| year_month | A particular month of a year. 6-digits with format CCYY-MM | ISO 8601 | 2019-01 |
| year | A year. 4-digits with format CCYY | ISO 8601 | 2019 |
Config Section
The "config" section — distinct within an overall API configuration — can be included at the end of a full API configuration or in the API request itself. It should be included in a saved API configuration.
The following example is a full configuration of Demyst's Business Firmographics Recipe.
The "config" section at the bottom dictates specific API behaviors.
Mode
Adding "config": { "mode" : MODE } to the JSON request payload can run a transaction in an alternate execution mode.
-
sample By default, this mode runs each provider using Demyst's internally saved static sample responses. This is the only allowed mode for a test API key; it does not need to be explicitly requested.
-
cache this mode checks Demyst's provider cache for a response before making a call to a data provider. If a user has called a provider in cache mode with identical inputs at some point in the previous 7 days, the response will be in the cache. Responses are added to the cache when a provider is called in cache mode and the response is not already in the cache.
-
cache_read_only This mode searches Demyst's provider cache for a response. It does not attempt a live call to any provider, and it returns an error if the response is not already present in the cache.
-
live This is the default mode for production keys, and it does not need to be explicitly requested. Live mode always calls new data from data sources.
Raw Data
The return_raw_data flag creates a new subsection under the response from each data provider. A true setting will return the raw data directly from the data provider. See more details on that section under the API Response description.
Flattened Data
The return_flattened_data flag creates a new subsection under the response from each data provider. A true setting will return the data parsed by Demyst and flattened down to a single level of key-value pairs. See more details on that section under the API Response description.
Fixed List Size
Data providers often return large lists of data, and the size of these lists can be arbitrary. By limiting the size of the lists, and therefore the overall number of attributes, responses can be simplified or made easier to use and more predictable for downstream processes.
The fixed_list_size information in the example above limits any list size to 3 — any element after that will be cut out of the raw data and parsed data responses. The default number is 10.
{
"providers": {
"everstring_company_enrichment": {
"version": "$latest"
},
"hosted_experian_cpdb": {
"version": "$latest"
},
"hosted_equifax_mds": {
"version": "$latest"
},
"hosted_infogroup_business_places": {
"version": "$latest"
},
"hosted_infogroup_business_places": {
"version": "$latest"
}
},
"refine": {
"sic_code": {
"$firstOf": [
"hosted_infogroup_business_places.results[0].primary_sic_code_id",
"hosted_equifax_mds.results[0].efx_primsic",
"hosted_experian_cpdb.results[0].prim_sic_code",
"everstring_company_enrichment.data[0].es_sic_4"
]
},
"naics_code": {
"$firstOf": [
"hosted_infogroup_business_places.results[0].primary_naics_code_id",
"hosted_equifax_mds.results[0].efx_primnaicscode",
"hosted_experian_cpdb.results[0].prim_naics_code",
"everstring_company_enrichment.data[0].es_naics_6"
]
},
"year_business_start": {
"$firstOf": [
"hosted_infogroup_business_places.results[0].estimated_opened_for_business_lower",
"hosted_equifax_mds.results[0].efx_yrest",
"hosted_experian_cpdb.results[0].year_business_started",
"everstring_company_enrichment.data[0].es_year_started"
]
},
"sales": {
"$firstOf": [
"hosted_infogroup_business_places.results[0].location_sales_volume",
"hosted_equifax_mds.results[0].efx_corpamount",
"hosted_experian_cpdb.results[0].est_annual_sales_amt",
"everstring_company_enrichment.data[0].es_revenue"
]
},
"no_of_employees": {
"$firstOf": [
"hosted_infogroup_business_places.results[0].estimated_location_employee_count",
"hosted_equifax_mds.results[0].efx_locempcnt",
"hosted_experian_cpdb.results[0].est_num_of_employees",
"everstring_company_enrichment.data[0].es_employee"
]
},
"phone": {
"$firstOf": [
"hosted_infogroup_business_places.results[0].phone",
"hosted_equifax_mds.results[0].efx_phone",
"hosted_experian_cpdb.results[0].phone",
"everstring_company_enrichment.data[0].es_company_phone"
]
},
"website": {
"$firstOf": [
"hosted_infogroup_business_places.results[0].website",
"hosted_equifax_mds.results[0].efx_web",
"hosted_experian_cpdb.results[0].url",
"everstring_company_enrichment.data[0].es_primary_website"
]
}
},
"config": {
"mode": "cache",
"return_raw_data":true
"return_flattened_data":true,
"fixed_list_size":3
}
}
Errors
| error_type | current_message | error_category | description | http_status |
|---|---|---|---|---|
| blackbelly_communications_link_failure | internal_error | An internal error has occurred. The Demyst team should be contacted so that it can be resolved. | 0 | |
| blackbelly_query_timeout | timeout | The data query took too long to process, for one of several possible reasons. | 0 | |
| blackbelly_table_does_not_exist | internal_error | An internal error has occurred. The Demyst team should be contacted so that it can be resolved. | 0 | |
| channel_access_denied | permission_error | The Demyst team should be contacted to ensure that the user can access the channel used by the request. | 0 | |
| channel_not_found | Channel with id 1103 not found | channel_not_found | The user should verify that they provided the correct channel for their request. | 0 |
| data_function_error | internal_error | An internal error has occurred. The Demyst team should be contacted so that it can be resolved. | 0 | |
| data_function_misses_result_key | internal_error | An internal error has occurred. The Demyst team should be contacted to fix a client-specific customization. | 200 | |
| data_function_response_error | Unexpected response received from DataFunction: data function did not return a result key, in pipe with id: Some(691) |
internal_error | No results were returned from a custom data function. Demyst support should be contacted. | 200 |
| decoding_error | upstream_structure_error | The data provider returned an unexpected response. Demyst support should be contacted. | 422 | |
| insufficient_api_key_permissions | The given apiKey is for test use only. It is only authorized for use with Sample mode |
permission_error | The API key provided by the user can only be used for test purposes in sample mode. | 400 |
| insufficient_channel_permissions | Organization with id 2 does not have permission to run Channel with id 1052 |
permission_error | The Demyst team should be contacted to ensure that the user can access the channel used by the request. | 403 |
| insufficient_credentials | insufficient_credentials | The Demyst team should be contacted to fix an access issue with a specific data provider. | 200 | |
| insufficient_input | Did not have sufficient valid input to run. Given valid inputs: InputField(email_address,Some(EmailAddress), \"ladylockett86@icloud.com\"), InputField(state,Some(State),\"QLD\"), InputField(country,Some(Country),\"AU\"), InputField(post_code,Some(PostCode),\"4159\"), InputField(last_name,Some(LastName),\"Schiffke\"), InputField(ip6,Some(Ip6), \"2001:8003:e122:4800:edac:8c6:c71e:bbd4\"), InputField(street,Some(Street),\"4 Clive Rd\"), InputField(phone,Some(Phone),\"+61467558685\"), InputField(first_name,Some(FirstName),\"Leah\"), InputField(city,Some(City),\"Birkdale\")" |
insufficient_input | The attempted configuration requires specific inputs to execute successfully. Verify that the correct inputs that were provided to the connector. | 200 |
| invalid_api_key | apiKey 236dfh453756... is invalid | permission_error | The user's API key is invalid, inactive, or missing a character. | 400 |
| invalid_credentials | Request was not authorized, the credentials you provided for this data source are likely invalid. |
invalid_credentials | The credentials — provided by either the client or by Demyst — for accessing a specific data provider are incorrect or out of date. | 200 |
| ip_whitelist_error | "Request came from 116.14.20.220, which is not on the ip whitelist for this organization. |
permission_error | The request came from an IP address that is not associated with the user's organization. The Demyst team should be contacted to update the IP whitelist. | 0 |
| logical_input_error | logical_input_error | The attempted query requires specific inputs that were not in the correct format. | 200 | |
| missing_provider_grants | permission_error | The user requested information from a data provider that requires special access privileges. Contact the Demyst team to discuss accessing this provider. | 0 | |
| network_error | upstream_error | A network error has occurred. The Demyst team should be contacted to resolve it. | 200 | |
| no_api_key_given | permission_error | The user did not provide the credentials that are necessary to access a specific data provider. | 0 | |
| provider_version_not_found | provider_version_not_found | The query attempted to access a data provider that was not recognized. The information in the original query should be checked for errors. | 400 | |
| rate_limit_exceeded | rate_limit_exceeded | A data provider has been contacted too frequently in too short a period of time; their rate limit has been exceeded. | 200 | |
| sample_data_not_implemented | sample_data_not_implemented | The API attempted to request sample data from a data provider that is not available. Contact Demyst support to discuss implementing sample data for this data provider. | 200 | |
| timeout | Timeout of 5 s exceeded. Cause: -" | timeout | The Demyst team will need to check the response to determine why the default timeout period has been exceeded. | 200 |
| uncaught_defect | internal_error | An unexpected error has occurred. The Demyst team should be contacted so that it can be resolved. | 200 | |
| unexpected_batch_record_error | internal_error | An unexpected error has occurred. The Demyst team should be contacted so that it can be resolved. | 200 | |
| unexpected_blackbelly_sql_error | internal_error | An unexpected error has occurred. The Demyst team should be contacted so that it can be resolved. | 200 | |
| unexpected_data_function_error | Data Function Exception: An error occurred and the request cannot be processed. (Service: AWSLambda; Status Code: 500; Error Code: ServiceException Data Function Exception: Unable to execute HTTP request: Timeout waiting for connection from pool, in pipe with id: Some(601) |
internal_error | The Demyst team will need to resolve the issue by identifying why the response from the provider has resulted in an error. | 0 |
| unexpected_provider_error | internal_error | The Demyst team will need to resolve the issue by identifying why the response from the provider has resulted in an error. | 200 | |
| unexpected_upstream_http_status | upstream_error | The Demyst team will need to resolve the issue by identifying why the response from the provider has resulted in an error. | 200 | |
| unexpected_upstream_structure | upstream_structure_error | The Demyst team will need to resolve the issue by identifying why the response from the provider has resulted in an XML/JSON parsing failure. | 200 | |
| upstream_application_error | Unknown Error or... Unknown city: PEACHTREE CORNERS, GA |
upstream_application_error | Either the requested data provider is down, or it returned an unexpected error. (Similar to upstream_service_unavailable) | 200 |
| upstream_service_unavailable | HTTP status code 503 unexpected || HTTP status code 500 unexpected |
upstream_error | Either the requested data provider is down, or it returned an unexpected error. (Similar to upstream_application_error) | 200 |
Demyst Catalog - RESTful API
Overview
This page details the RESTful API for pulling catalog details that can aid with catalog integration with a third-party tool (such as ckan, data.world) or any other bespoke destination.
API Calls for Catalog
- GET JWT TOKEN
To get the JWT token required for calls to our API, the following cURL request can be used (or imported to an API platform like Postman as a raw test or can be put into the terminal of your computer). Substitute the dummy variables [EMAIL] and [PASSWORD] with your email address and password credentials for accessing our API.
curl --location --request POST 'https://console.demystdata.com/jwt/create' \
--header 'Content-Type: application/json' \
--data-raw '{
"email_address": "[EMAIL]",
"password": "[PASSWORD]"
}'
The response of this request will replace the variable [BEARER] in the calls below, copy and paste it exactly as it is output.
- List of Connectors and Basic Metadata
The endpoint to access our entire list of available providers/APIs/connectors provides general metadata rather than the heavier payload of a call to a specific provider. This provides a queryable overview of the list of products we offer.
This process is two-part: the cURL request for accessing the total number of providers (an ever-changing and growing value), and the cURL request to use that total number of providers for an unpaginated view of the list of products. Part1:
curl --location --request GET 'https://console.demystdata.com/catalog/providers' \
--header 'Authorization: Bearer [BEARER]' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json'
The total number of accessible providers is the value total_entries in the "pagination" dictionary at the top of the response. Use this value to replace the variable [TOTAL_ENTRIES] in Part 2. Part2:
curl --location --request GET 'https://console.demystdata.com/catalog/providers?per_page=[TOTAL_ENTRIES]' \
--header 'Authorization: Bearer [BEARER]' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json'
From this list, we can use the id or name of a specific product to make the below calls.
- List Input and Output fields/Schema of a single Connector
When you have identified the id value for the product of which you'd like more than basic metadata (or specifically, you need the input and output schema), use the below request and replace [ID].
curl --location --request GET 'https://console.demystdata.com/catalog/providers/[ID]' \
--header 'Authorization: Bearer [BEARER]' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json'
For example let's use the provider of the name hosted_equifax_ixi_ability_to_pay which can be viewed on our platform here: Demyst: The Data Deployment Platform. From the aforementioned cURL request of the entire list of providers with basic metadata, we see that this product has identifier id: 1490. Substituted into the directly-above request, this will become:
curl --location --request GET 'https://console.demystdata.com/catalog/providers/1490' \
--header 'Authorization: Bearer [BEARER]' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json'
The entire sample output will be like below. The schema can be found at the following locations:
- Input Schema Location →
.latest_version.schema[0].input
- Output Schema Location → .latest_version.schema[0].output
If you are more specifically interested in required or optional input attributes, these can be found at:
- Required Inputs → .latest_version.schema[0].input.required
- Optional Inputs → .latest_version.schema[0].input.optional
Entire sample output:
{
"adx_flag":false,
"alias":"IXI - Ability to Pay Index",
"data_update_frequency":null,
"description":"Ability to Pay (ATP) Index™ provides insight into a household's estimated financial position by ranking households by their likely economic capacity. It is delivered as a household-level score of 1-1000 which ranks households based on their financial ability to pay financial obligations or incur new ones. ATP Index incorporates estimated total income, discretionary spending, and aggregated credit to provide a more complete measure of capacity than using only one of these measures alone. It is intended for use in non-FCRA marketing applications only.",
"diligence_tag":"Conditionally Approved",
"dppa":false,
"fcra":false,
"featured":false,
"glba":false,
"id":1490,
"logo":"https://console.demystdata.com/assets/equifax-e721c85699facdb021ce0491fa03126e97ae914c18f38a6f90c8c47ae86809ec.svg",
"name":"hosted_equifax_ixi_ability_to_pay",
"notes":"Internal Diligence Notes - Data may not be used a factor in establishing an individual's eligibility for credit, insurance, employment, or any other permissible purpose for which a consumer report may be used under the FCRA or in any way for the purpose of taking "adverse action" against a consumer, as defined in the Equal Credit Opportunity Act (ECOA) and Regulation B (vendor)",
"product_type":"Full Release",
"text_conditionally_approved":"Conditions: For use in non-FCRA B2C marketing uses cases.",
"credit_price":"7.0",
"error_rate":1.0,
"hit_rate":0.0,
"data_source":{
"name":"Equifax",
"website":"https://www.equifax.com"
},
"data_category":{
"name":"People"
},
"data_regions":[
{
"name":"United States"
}
],
"tags":[
{
"name":"Consumer behavioral",
"description":"Consumer behavioral data (i.e. related to activities, interests & intent)",
"category":"SubEntity(Data-Category)"
},
{
"name":"Consumer transactional and financial",
"description":"Consumer historical transactional & financial data",
"category":"SubEntity(Data-Category)"
},
{
"name":"Application Pre-fill",
"description":"In order to assess the risk associated with a particular business, individual or property, an insurer must collect information about the insured. Whilst a short list of factors is easily to collect from a customer, it is typically not enough to be able to assess the risk associated to them and so an underwriting process often has a long list of items that must be known about an entity seeking insurance. Without having external data in order to make this assessment, the customer is forced to provide a large amount of information upfront which undermines their experience, causing drop-offs in applications and is also prone to errors and omissions. By having access to external data about an individual, an insurer is able to pre-fill an application with information for confirmation by an individually rather than through self-declaration which can be prone to both incorrect inputs and 'too-much-effort' drop-offs.",
"category":"Use-Case"
},
{
"name":"Lead Targeting",
"description":"A FI's outbound new customer acquisition is a function of the amount and quality of leads. Low conversion rates are typically a result of a lack of data enrichment resulting in poorly optimised marketing campaigns that include customers outside the FI's target market. Specific marketing channels (e.g. digital vs call centre) will also favour different types of leads, but without more characteristics on the lead, no triage can take place. By leveraging external data sources, a FI can access a more expansive list of potential customers, enrich them with additional attributes and filtered to those with desirable characteristics. This can be enhanced with machine learning techniques where available data about converted leads can be used to inform a lead scoring model specific to the FI's experience, improving conversion rates even more over time. Finally, based off a lead score and carefully chosen characteristics, channel triaging can occur to direct leads to the channel most likely to result in their conversion.",
"category":"Use-Case"
},
{
"name":"Portfolio Monitoring",
"description":"A FI's existing customer retention and cross-sell strategy is a function of the amount of information available about an existing customer. Knowing which customers are likely to churn or which you are not capturing their entire share of wallet is necessary to not waste retention marketing resources, or impact customer experience by conducting outreach to non-churning customers. By leveraging external data sources, a bank or insurer can monitor changes in a customer's enriched profile, such as lifestage, lifestyle or property attributes as indications of new cross-sell opportunities or risks of retention. Using an extended set of variables about each customer and actual churn experiences, a bank or insurer's can develop propensity to churn models specific to the bank's experience to further focus retention efforts with optimal offers, prompts and assistance.",
"category":"Use-Case"
},
{
"name":"eCommerce",
"description":"",
"category":"Industry"
}
],
"latest_version":{
"id":10368,
"schema":[
{
"input":{
"optional":[
{
"name":"age_band",
"type":"Integer"
},
{
"name":"earliest_snapshot",
"type":"Date"
},
{
"name":"latest_snapshot",
"type":"Date"
}
],
"required":[
[
{
"name":"post_code",
"type":"PostCode"
},
{
"name":"post_code_extension",
"type":"String"
},
{
"name":"country",
"type":"Country"
}
]
]
},
"output":[
{
"name":"is_hit",
"type":"Boolean"
},
{
"name":"results",
"type":"List",
"children":[
{
"name":"post_code",
"type":"PostCode"
},
{
"name":"post_code_extension",
"type":"String"
},
{
"name":"age_band",
"type":"Integer"
},
{
"name":"atp",
"type":"Integer"
},
{
"name":"country",
"type":"Country"
},
{
"name":"date",
"type":"Date"
}
]
}
]
}
],
"version":9,
"input_fields":[
{
"description":"4 digit ZIP + 4",
"log_flattened_name":"post_code_extension",
"name":"post_code_extension",
"type":"String"
},
{
"description":null,
"log_flattened_name":"latest_snapshot",
"name":"latest_snapshot",
"type":"Date"
},
{
"description":null,
"log_flattened_name":"earliest_snapshot",
"name":"earliest_snapshot",
"type":"Date"
},
{
"description":"5 digit Zip code",
"log_flattened_name":"post_code",
"name":"post_code",
"type":"PostCode"
},
{
"description":"ISO 2 code for country",
"log_flattened_name":"country",
"name":"country",
"type":"Country"
},
{
"description":"Age band value from 0 to 7. 0 - Default. 1 - 18 to 24. 2 - 25 to 34. 3 - 35 to 44. 4 - 45 to 54. 5- 55 to 64. 6 - 65 to 74, 7 - 75 to 111",
"log_flattened_name":"age_band",
"name":"age_band",
"type":"Integer"
}
],
"output_fields":[
{
"description":"Boolean indicating the match",
"field_is_populated_rate":0.0,
"log_flattened_name":"is_hit",
"name":"is_hit",
"type":"Boolean"
},
{
"description":"5 digit Zip code",
"field_is_populated_rate":1.0,
"log_flattened_name":"results[*].post_code",
"name":"post_code",
"type":"PostCode"
},
{
"description":"4 digit ZIP + 4",
"field_is_populated_rate":1.0,
"log_flattened_name":"results[*].post_code_extension",
"name":"post_code_extension",
"type":"String"
},
{
"description":"Age band value from 0 to 7. 0 - Default. 1 - 18 to 24. 2 - 25 to 34. 3 - 35 to 44. 4 - 45 to 54. 5- 55 to 64. 6 - 65 to 74, 7 - 75 to 111",
"field_is_populated_rate":1.0,
"log_flattened_name":"results[*].age_band",
"name":"age_band",
"type":"Integer"
},
{
"description":"A modeled continuous score of 1-1000 that ranks customers based on their estimated financial capacity and/or ability to pay debt(s), with a rating of 1000 being the most likely to be able to pay financial obligations. Derived from IXI's Financial Assets Database, it examines the relationship between spending, income and other variables to assess consumers' ability to pay.",
"field_is_populated_rate":1.0,
"log_flattened_name":"results[*].atp",
"name":"atp",
"type":"Integer"
},
{
"description":"ISO 2 code for country",
"field_is_populated_rate":1.0,
"log_flattened_name":"results[*].country",
"name":"country",
"type":"Country"
},
{
"description":"Date the data was delivered and ingested by Demyst",
"field_is_populated_rate":1.0,
"log_flattened_name":"results[*].date",
"name":"date",
"type":"Date"
},
{
"description":"Data container",
"field_is_populated_rate":null,
"log_flattened_name":"results",
"name":"results",
"type":"List"
}
]
},
"output_fields":[
{
"description":"Boolean indicating the match",
"field_is_populated_rate":0.0,
"log_flattened_name":"is_hit",
"name":"is_hit",
"type":"Boolean"
},
{
"description":"5 digit Zip code",
"field_is_populated_rate":1.0,
"log_flattened_name":"results[*].post_code",
"name":"post_code",
"type":"PostCode"
},
{
"description":"4 digit ZIP + 4",
"field_is_populated_rate":1.0,
"log_flattened_name":"results[*].post_code_extension",
"name":"post_code_extension",
"type":"String"
},
{
"description":"Age band value from 0 to 7. 0 - Default. 1 - 18 to 24. 2 - 25 to 34. 3 - 35 to 44. 4 - 45 to 54. 5- 55 to 64. 6 - 65 to 74, 7 - 75 to 111",
"field_is_populated_rate":1.0,
"log_flattened_name":"results[*].age_band",
"name":"age_band",
"type":"Integer"
},
{
"description":"A modeled continuous score of 1-1000 that ranks customers based on their estimated financial capacity and/or ability to pay debt(s), with a rating of 1000 being the most likely to be able to pay financial obligations. Derived from IXI's Financial Assets Database, it examines the relationship between spending, income and other variables to assess consumers' ability to pay.",
"field_is_populated_rate":1.0,
"log_flattened_name":"results[*].atp",
"name":"atp",
"type":"Integer"
},
{
"description":"ISO 2 code for country",
"field_is_populated_rate":1.0,
"log_flattened_name":"results[*].country",
"name":"country",
"type":"Country"
},
{
"description":"Date the data was delivered and ingested by Demyst",
"field_is_populated_rate":1.0,
"log_flattened_name":"results[*].date",
"name":"date",
"type":"Date"
},
{
"description":"Data container",
"field_is_populated_rate":null,
"log_flattened_name":"results",
"name":"results",
"type":"List"
}
],
"current_organizations_credit_price":null
}
Pull the CSV File Link for sample data for a single Connector
To pull the URL from which to get the sample data of a single connector, use the following cURL request:
curl --location --request POST 'https://console.demystdata.com/table_providers/[ID]/download_sample_data' \
--header 'Authorization: Bearer [BEARER]' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json'
We will again use the provider with name hosted_equifax_ixi_ability_to_pay (viewable on our platform here: Demyst: The Data Deployment Platform) and id: 1490. Replacing [ID] becomes:
curl --location --request POST 'https://console.demystdata.com/table_providers/1490/download_sample_data' \
--header 'Authorization: Bearer [BEARER]' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json'
Within the output of this request will be a URL that will look something like "url": "[SAMPLE_DATA_URL]". Copy the entirety of the link provided in the response and use the following:
curl --location --request GET '[SAMPLE_DATA_URL]'
To view CSV formatted sample data for the product.
Search through RESTful API
Demyst's Search functionalities are also available through RESTful APIs that can be integrated into any third party app or coded in to any language to enable searching for products for any specific use-cases.
Get JWT token
Generating a JWT is a prerequisite for some of the calls below. It can be substituted with an API Key as well, which does not expire like a JWT (24-hour expiration). Check the Demyst documentation on JWT creation using an email and password, or generate an API key through the Team Settings page. Returned token (or API Key) to be substituted below in each call where there is: [BEARER].
List of all Demyst Filters
Demyst provides filters to narrow your search and find the connectors for a specific use-case. These filters are
-
tags[]
-
data_sources[]
-
regions[]
-
categories[]
-
featured[]
For all of these parameter keys except featured (which is a boolean, and 'false' by default), there are set values that the user may want to know if they are not already familiar with the platform.
The list of all possible tags[] to use for searching is available through the following call, along with a tag description and tag category (the category discerns whether the tag is a use-case, part of a common grouping of data / "data-category", or a type of industry):
curl --location --request GET 'https://console.demystdata.com/tags' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer [BEARER]'
To view the data_sources[] in our catalog:
curl --location --request GET 'https://console.demystdata.com/catalog/data_sources' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer [BEARER]'
To view the regions[] we have available so far:
curl --location --request GET 'https://console.demystdata.com/regions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer [BEARER]'
To view the primary categories[] / entities:
curl --location --request GET 'https://console.demystdata.com/categories' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer [BEARER]'
Search functionality works best using Demyst Filters. There is some leniency with tags[] but for accuracy and easy troubleshooting, it is recommended to use the full tag and not keywords. Further, if a value in regions[] is either unrecognized (spelling) or not a primary region (e.g. Papua New Guinea), the connectors with Global coverage will be returned to suit this match.
Search
The URL for searching with the above filters will be:
https://console.demystdata.com/catalog/providers
An HTTPS request to this endpoint will be a GET method with the aforementioned (listed below as well) options for parameters. These parameters can be combined in any way that best expresses the requirement(s) for the use-case(s).
-
tags[]
-
data_sources[]
-
regions[]
-
categories[]
-
featured[]
Putting all of these together, we can filter the catalog for quite a strict search. The following example looks only through the Pipl and Ekata data sources, where we want products that cover the Singapore region, falls into the primary data category of People, and contains the "Consumer ID Validation" tags for our use-case.
curl --location -g --request GET 'https://console.demystdata.com/catalog/providers?data_sources[]=Pipl&data_sources[]=Ekata®ions[]=Singapore&categories[]=People&tags[]=Consumer ID verification' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer [BEARER]'
From this example we receive back 3 connectors:
{
"pagination": {
"current_page": 1,
"total_pages": 1,
"total_entries": 3
},
"providers": [
{
"alias": "Ekata Identity Check",
"description": "The Ekata Identity Engine is what powers Ekata's digital identity verification API, which returns more than 70 data signals and insights from a single query. Built specifically for decisioning platforms, the Ekata Identity Engine leverages real-time global data, pattern recognition, machine learning, and data science across the five core identity elements of Email, Name, Phone, IP, and Address to provide businesses a clear picture of consumers. The Ekata Identity Engine is composed of two distinct and mutually exclusive data sources: the Ekata Identity Graph and the Ekata Identity Network. These datasets transform into unique and valuable insights that allow organizations to combat fraud, build trust, and grow revenue with frictionless customer experiences.",
"dppa": false,
"fcra": false,
"glba": false,
"id": 7,
"logo": "https://demyst-public.s3.amazonaws.com/icons/aegean_data_source/7/icon/Ekata.svg",
"name": "white_pages_pro",
"data_source": {
"name": "Ekata"
},
"data_category": {
"name": "People"
},
"data_regions": [
{
"name": "Global"
}
],
"tags": [
{
"name": "Consumer ID verification",
"description": "Consumer identity data for verification purposes",
"category": "SubEntity(Data-Category)"
},
{
"name": "KYC Workflow Automation",
"description": "A regulated financial services firm obligations to conduct know-your-customer (KYC) checks on consumer that it wishes to do business with. This involves confirming that a customer is who they say they are to in order to reduce fraud, AML and other bad-actor risks. This is typically conducted as a manual time-intensive review of potential consumers in which the consumer's information need be verified for authenticity. This is costly in resource but can also result in a loss of business as consumers will prefer simpler solution with faster approval times. By leveraging external data sources, a regulated financial services organisation can replace this with an automated process that can verify a consumer and flag for relevant risks in real-time, reducing manual reviews to only those that require it and providing a more seamless customer experience.",
"category": "Use-Case"
},
{
"name": "Application Pre-fill",
"description": "In order to assess the risk associated with a particular business, individual or property, an insurer must collect information about the insured. Whilst a short list of factors is easily to collect from a customer, it is typically not enough to be able to assess the risk associated to them and so an underwriting process often has a long list of items that must be known about an entity seeking insurance. Without having external data in order to make this assessment, the customer is forced to provide a large amount of information upfront which undermines their experience, causing drop-offs in applications and is also prone to errors and omissions. By having access to external data about an individual, an insurer is able to pre-fill an application with information for confirmation by an individually rather than through self-declaration which can be prone to both incorrect inputs and 'too-much-effort' drop-offs.",
"category": "Use-Case"
}
]
.
.
.
},
{
"alias": "Ekata Account Opening",
"description": "Account Opening assesses the overall risk of an applicant for a new account. Using the inputs of name, phone, address, email, and IP, the dataset returns 23 highly predictive identity verification features from Ekata's Identity Graph and Identity Network.",
"dppa": false,
"fcra": false,
"featured": false,
"glba": false,
"id": 2652,
"logo": "https://demyst-public.s3.amazonaws.com/icons/aegean_data_source/7/icon/Ekata.svg",
"name": "Ekata_Account_Opening",
"data_source": {
"name": "Ekata"
},
"data_category": {
"name": "People"
},
"data_regions": [
{
"name": "Global"
}
],
"tags": [
{
"name": "Consumer ID verification",
"description": "Consumer identity data for verification purposes",
"category": "SubEntity(Data-Category)"
},
{
"name": "Digital asset risks",
"description": "Validation of emails, phone, IPs and domains including associated risks or peripheral information for these. ",
"category": "SubEntity(Data-Category)"
}
]
},
{
"alias": "",
"description": "Ekata Transaction Risk API provides predictive identity verification insights to help businesses fight payment fraud and improve the approval rates for all types of transactions in both pre- and post-auth workflows. Transaction Risk API leverages real-time global data, network insights, and machine learning to provide businesses a clear picture of how risky their transactions are. Transaction Risk API features transaction-level intelligence that offers insights into addresses previously used online, extremely low latency that delivers signals in under 100ms, and global coverage across 249 countries and territories. ",
"dppa": false,
"fcra": false,
"featured": false,
"glba": false,
"id": 2684,
"logo": "https://demyst-public.s3.amazonaws.com/icons/aegean_data_source/7/icon/Ekata.svg",
"name": "ekata_transaction_risk",
"data_source": {
"name": "Ekata"
},
"data_category": {
"name": "People"
},
"data_regions": [
{
"name": "Global"
}
],
"tags": [
{
"name": "Consumer ID verification",
"description": "Consumer identity data for verification purposes",
"category": "SubEntity(Data-Category)"
},
{
"name": "KYC Workflow Automation",
"description": "A regulated financial services firm obligations to conduct know-your-customer (KYC) checks on consumer that it wishes to do business with. This involves confirming that a customer is who they say they are to in order to reduce fraud, AML and other bad-actor risks. This is typically conducted as a manual time-intensive review of potential consumers in which the consumer's information need be verified for authenticity. This is costly in resource but can also result in a loss of business as consumers will prefer simpler solution with faster approval times. By leveraging external data sources, a regulated financial services organisation can replace this with an automated process that can verify a consumer and flag for relevant risks in real-time, reducing manual reviews to only those that require it and providing a more seamless customer experience.",
"category": "Use-Case"
},
{
"name": "Application Pre-fill",
"description": "In order to assess the risk associated with a particular business, individual or property, an insurer must collect information about the insured. Whilst a short list of factors is easily to collect from a customer, it is typically not enough to be able to assess the risk associated to them and so an underwriting process often has a long list of items that must be known about an entity seeking insurance. Without having external data in order to make this assessment, the customer is forced to provide a large amount of information upfront which undermines their experience, causing drop-offs in applications and is also prone to errors and omissions. By having access to external data about an individual, an insurer is able to pre-fill an application with information for confirmation by an individually rather than through self-declaration which can be prone to both incorrect inputs and 'too-much-effort' drop-offs.",
"category": "Use-Case"
}
]
}
]
}
Related connectors
If your above call (or a call for the entire Demyst Catalog) returned a connector to which you would like to view related connectors, this can be done by using the id attribute of the returned connector. Looking at the first returned connector of our example above, that would be "id": 7 on line 14.
How a connector is defined as related is through a number of sophisticated relations and tags. As an example, for the provider bing, which has an id of 61, related connectors would be those with the "Search engine" tag. This id is used in the URL, like so:
curl --location --request GET 'https://console.demystdata.com/catalog/providers/61/related' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer [BEARER]'
The output of this call has the following format:
[
{
"alias": "",
"description": "Nomino Negative Media enables you to search the latest negative media, for screening and researching individuals and entities. ",
"dppa": false,
"fcra": false,
"glba": false,
"id": 2440,
"logo": "https://demyst-public.s3.amazonaws.com/icons/aegean_data_source/462/icon/Screen_Shot_2019-08-28_at_10.20.03_AM.png",
"name": "nomino_data_negative_media",
"product_type": "Full Release",
"tags": [
"Search engine"
],
"data_source": {
"name": "Nomino Data"
}
},
{
"alias": "WhoisXML Domain Availability",
"description": "Domain Availability API helps you check whether a domain name is available for registration.",
"dppa": false,
"fcra": false,
"glba": false,
"id": 2609,
"logo": "https://demyst-public.s3.amazonaws.com/icons/aegean_data_source/669/icon/1604381643450.jpeg",
"name": "whoisxmlapi_domain_availability",
"product_type": "Full Release",
"tags": [
"Search engine"
],
"data_source": {
"name": "WhoisXML"
}
},
{
"alias": "Bing V7",
"description": "Bing is an internet search engine. This is version 7 of the Bing Web Search API, which enables safe, ad-free, location-aware search results. Bing records the type of device a person is using, what the user searched for, and when the user searched for it. Bing stores search terms and cookie IDs separately from the personal information of who conducted the search. ",
"dppa": false,
"fcra": false,
"glba": false,
"id": 2626,
"logo": "https://console.demystdata.com/assets/bing-e3f8f102880cbf0aba347cb4cc83d615ea7c9f4aacf99d5ac45526086deecb2e.svg",
"name": "bing_v7",
"product_type": "Full Release",
"tags": [
"Search engine"
],
"data_source": {
"name": "Bing"
}
}
]
Loose Search
If the user does not necessarily need to match on a specific filter or through specific tags/relations, then there is additionally the option to search with any phrase or keywords. This could be used to search for inputs or tags as well, but the result is a response with relevance scoring and details on such, which may not be necessary or desired. Additionally, we recommend using the call most specific to your use-case.
This loose search works as precisely as the keywords in the search query. This only slightly affects phrases, such as "machine learning", where the phrase is broken up to also search on the individual words to maximize relevance. This means that some of the returned matching connectors may be those with attributes that matched on either "machine" (i.e. "machinery") or "learning". For "machine learning" we do see, however, that the majority of matched connectors are by the description. Try the following call, where the return can then be parsed for where relevance_score_details.description.value = 1.
Where this method shines is when one has search needs such as "marketability" (e.g. only interested in products where the use is so specific to being used for marketability that it would definitely be in a connector's description somewhere) or "AVM" (which is neither tag nor input, and searching by "property/properties" returns too many products).
Using the "AVM" example our search call would look like such:
curl --location --request GET 'https://console.demystdata.com/catalog/providers?search=AVM&per_page=1000' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer [BEARER]'
And the returned connectors will have the following format (results are shortened for length consideration):
{
"pagination": {
"current_page": 1,
"total_pages": 1,
"total_entries": 14
},
"providers": [
{
"adx_flag": false,
"alias": "Clear Capital AVM",
"description": "This Clear Capital AVM product is Clear Capital's ClearAVM API that delivers values for 136+ million addresses in the United States. This AVM API is an Automated Valuation Model- an analytical model that helps predict the market value of residential property by considering characteristics, data density and other market analytics derived from many different data sources; including but not limited to County Tax Assessor, County Recorder, and Listing Information. The ClearAVM data is updated hourly, and provides the largest compliant property information data set in the country.",
"dppa": false,
"fcra": false,
"featured": true,
"glba": false,
"id": 2638,
"logo": "https://demyst-public.s3.amazonaws.com/icons/aegean_data_source/839/icon/clearcapital.jpeg",
"name": "clearcapital_avm",
"data_source": {
"name": "Clear Capital"
},
"data_category": {
"name": "Property"
},
"data_regions": [
{
"name": "United States"
}
],
"tags": [
{
"name": "Property commercial - Listings, transactions and valuation",
"description": "Historical listing, transaction and valuation data related to commercial properties",
"category": "SubEntity(Data-Category)"
},
{
"name": "Property residential - Listings, transactions and valuation",
"description": "Historical listing, transaction and valuation data related to residential properties",
"category": "SubEntity(Data-Category)"
},
{
"name": "Application Pre-fill",
"description": "In order to assess the risk associated with a particular business, individual or property, an insurer must collect information about the insured. Whilst a short list of factors is easily to collect from a customer, it is typically not enough to be able to assess the risk associated to them and so an underwriting process often has a long list of items that must be known about an entity seeking insurance. Without having external data in order to make this assessment, the customer is forced to provide a large amount of information upfront which undermines their experience, causing drop-offs in applications and is also prone to errors and omissions. By having access to external data about an individual, an insurer is able to pre-fill an application with information for confirmation by an individually rather than through self-declaration which can be prone to both incorrect inputs and 'too-much-effort' drop-offs.",
"category": "Use-Case"
},
{
"name": "Lead Targeting",
"description": "A FI's outbound new customer acquisition is a function of the amount and quality of leads. Low conversion rates are typically a result of a lack of data enrichment resulting in poorly optimised marketing campaigns that include customers outside the FI's target market. Specific marketing channels (e.g. digital vs call centre) will also favour different types of leads, but without more characteristics on the lead, no triage can take place. By leveraging external data sources, a FI can access a more expansive list of potential customers, enrich them with additional attributes and filtered to those with desirable characteristics. This can be enhanced with machine learning techniques where available data about converted leads can be used to inform a lead scoring model specific to the FI's experience, improving conversion rates even more over time. Finally, based off a lead score and carefully chosen characteristics, channel triaging can occur to direct leads to the channel most likely to result in their conversion.",
"category": "Use-Case"
}
],
"relevance_score": 11.8,
"relevance_score_details": {
"search_words": [
"AVM"
],
"search_tokens": [
"(?i-mx:AVM)"
],
"whole_words_in_name_or_alias": {
"matches": [
"AVM"
],
"value": 1.0
},
"name": {
"matches": [
"clearcapital_avm"
],
"value": 3
},
"alias": {
"matches": [
"Clear Capital AVM",
"ClearCapitalAVM"
],
"value": 6
},
"data_source": {
"name": {
"matches": [],
"value": 0
}
},
"data_category": {
"name": {
"matches": [],
"value": 0
}
},
"description": {
"matches": [
"This Clear Capital AVM product is Clear Capital's ClearAVM API that delivers values for 136+ million addresses in the United States. This AVM API is an Automated Valuation Model- an analytical model that helps predict the market value of residential property by considering characteristics, data density and other market analytics derived from many different data sources; including but not limited to County Tax Assessor, County Recorder, and Listing Information. The ClearAVM data is updated hourly, and provides the largest compliant property information data set in the country."
],
"value": 1
},
"tags": {
"matches": [],
"value": 0
},
"latest_version": {
"required_input_names": {
"matches": [],
"value": 0.0
},
"required_input_types": {
"matches": [],
"value": 0.0
},
"optional_input_names": {
"matches": [
"retro_avm_effective_date"
],
"value": 0.1
},
"optional_input_types": {
"matches": [],
"value": 0.0
},
"output_names": {
"matches": [
"avm_pdf_link",
"avm_result",
"avm_type"
],
"value": 0.30000000000000004
},
"output_types": {
"matches": [],
"value": 0.0
}
},
"output_fields": {
"name": {
"matches": [
"avm_type",
"avm_result",
"avm_effective_date",
"avm_pdf_link"
],
"value": 0.4
},
"description": {
"matches": [],
"value": 0.0
}
}
}
},
.
.
.
]
}
Pagination
For the last couple of example calls here, the optional parameter per_page was snuck in. This is helpful when the amount of returned connectors is expected to be high, such as in a loose or broad search. There are two ways to navigate a large number of returned connectors that may not all fit on one (or the first) page:
-
per_page
-
page
The first of these, per_page, may be set at whatever integer the user requires and there is no harm in this being set to a large number. For searching through RESTful API the default number of returned connectors per page is 24.
The second of the options above, page, may be used if the user needs to keep the returned connectors per page smaller than 25. If this is the case, then the user's current page will be modified to reflect this in the returned "pagination" section.
An example would be searching for providers with regional coverage in Japan, and with no other filters. This will return all connectors that have Global coverage because Japan is not currently a set region for our catalog (available regions[] can be confirmed through making a call to the /regions endpoint). To navigate to the second page of returned results, the call becomes:
curl --location -g --request GET 'https://console.demystdata.com/catalog/providers?regions[]=Japan&page=2' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer [BEARER]'
The "pagination" section will update as shown here:
{
"pagination": {
"current_page": 2,
"total_pages": 8,
"total_entries": 188
},
"providers": [
{
"alias": "",
"description": "IFI CLAIMS Patent Services has been dedicated to enriching and curating patent information since the 1950s. IFI CLAIMS specializes in annotating and classifying patent and scientific documentation using expert curators and intelligent technologies. IFI continues the tradition of enabling access to high quality patent data with CLAIMS Direct -- an open data platform and web service providing access to the IFI CLAIMS Global Patent database. CLAIMS Direct can be accessed via web services, installed in the cloud or in a local data center. It can allow the user complete control of their own patent database. The robust API allows easy integration of a comprehensive database into 3rd party applications.\r\n\r\n",
"dppa": false,
"fcra": false,
"featured": false,
"glba": false,
"id": 1574,
"logo": "https://demyst-public.s3.amazonaws.com/icons/aegean_data_source/474/icon/image.png",
"match_rate": null,
"name": "ifi_citations",
"data_source": {
"name": "IFI Claims"
},
"data_category": {
"name": "Business"
},
"data_regions": [
{
"name": "Global"
}
],
"tags": [
{
"name": "Business registry",
"description": "Legal registration details for a business from its jurisdictional registry",
"category": "SubEntity(Data-Category)"
},
.
.
.
]
},
.
.
.
]
}
Batch Enrichment through RESTful API
This section will list the RESTful APIs calls to enrich a batch file (CSV) through a Data API or a Connector. The Bearer(JWT) token for this enrichment will be generated through the same process (Username + Password that expires every 90 days sent to https://console.demystdata.com/jwt/create). The token can also be replaced with an API key generated through the Settings page of the platform. Demyst recommends IP whitelisting with an API key for security.
Getting an Input File ready
The input file for batch enrichment should contain only the data and no headers. The rows should be well separated through a newline and cells separated by a comma. If the separator(comma) exists as a value in a cell, stringify the contents of the CSV with double quotes. Below is an example of a file with only one column
support@demystdata.com
client@demystdata.com
Listing Region IDs
To start an enrichment, you will need to get the region ID for your enrichment. This reflects the region of the connector or the Data API you made. An incorrect region could give you a Provider does not exist in this region error. Global connectors can resort to the region of your organization.
curl --location --request GET 'https://console.demystdata.com/list_regions' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer xxxxx'
The response will be a list of IDs and Region Names. For this example, we will go with the US region
[
{
"id":1,
"name":"United States",
"code":"us"
}
]
Generate Pre-Signed URL for uploading Input File
For uploading the Input CSV File, we will generate a Pre-signed URL (active for 15 minutes) along with the S3 Object Key using the Region ID from above. A new Pre-signed URL should be generated once it expires. The process helps to securely scan and upload a file to the Demyst Platform.
curl -X GET 'https://console.demystdata.com/presigned_batch_upload_url' \
--header 'content-type: application/json' \
--header 'Accept: application/json' \
--header 'Authorization: Bearer xxxx' \
--data-raw '{
"region_id": 1
}
The response will be a URL and Object Key as below
{
"presigned_url": "PRESIGNED_URL_TO_UPLOAD_FILE",
"s3_object_key": "batches/2ec89768-7183-1234-92a8-486961cb4716"
}
Uploading Input File to the Pre-Signed URL
Now that we have the URL, we can use it to upload our CSV file. There will be no response body but only a 200 response code if the file is successfully uploaded
curl --upload-file input_file.csv 'PRESIGNED_URL_TO_UPLOAD_FILE'
If you are trying to do this through POSTMAN or some other tool, change the upload cURL request to below and manually select the file/path to file.
curl --location --request PUT 'PRESIGNED_URL_TO_UPLOAD_FILE'
--form 'data=@"/Users/demyst-user/Documents/input_file.csv"'
Defining Batch Input and Generating Batch Input ID
Now that we have successfully uploaded our file, we will need to define the Batch Input to get the batch input ID before we start this batch enrichment. To get the batch input id, you will need the following
-
List of Headers - The list should define the headers and must be as per Demyst Types [Add hyperlink here]
-
Name of the Batch Input - Demyst suggests unique names. You could use the S3 Object Key generated with the Upload URL and append it with your file name.
-
Num Rows - Total rows in your file for enrichment. In the example here it is 2
-
Region ID - As described above and 1 (US) in the example here
-
S3 Object Key - Generated with the Upload URL
curl -X POST https://console.demystdata.com/aegean_batch_inputs \
-H 'content-type: application/json' \
-H "authorization: Bearer xxxx" \
-H 'accept: application/json' \
-d '
{
"aegean_batch_input": {
"headers": ["email_address"],
"name": "batches/2ec89768-7183-1234-92a8-486961cb4716/input_file.csv",
"num_rows": 2,
"region_id": 1,
"s3_object_key": "batches/2ec89768-7183-1234-92a8-486961cb4716"
}
}'
The response will provide you with the Batch Input ID which is needed for starting the Batch Enrichment. In this example, the ID is 45991
{
"id": 45991,
"name": "input_file.csv",
"region_id": 1,
"created_at": "2022-10-18T03:09:38.000Z",
"updated_at": "2022-10-18T03:09:38.000Z",
"headers": [
"email_address"
],
"num_rows": 2,
"organization_id": 2
}
Starting a Batch and getting Enrich ID
This is the last step for successfully starting your batch after uploading your Input file and getting a Batch ID. For this step, you will need the following details
-
Aegean Batch Input ID - The Batch ID generated from the previous step. Here it will be 45991. (Aegean is an internal Demyst term)
-
Name - The name of the batch enrichment is different from the name of the Aegean Batch Input that was described in the previous step. Demyst suggests having a name that is a combination of - Use-case/channel ID + username + date. Although, teams can set their own nomenclature.
-
Channel ID - This will be the Data API ID that you created. You can also run individual or a group of connectors if needed but Demyst recommends creating a Data API and using it to run.
-
Region ID - 1(US) in this example
curl -X POST https://console.demystdata.com/aegean_batch_runs \
-H 'content-type: application/json' \
-H "authorization: Bearer xxx"\
-H 'accept: application/json' \
-d '
{
"aegean_batch_run": {
"aegean_batch_input_id": 45991,
"name": "email-validation-hsingh@demystdata.com-2022-10-19",
"channel_id": 6292,
"region_id": 1
}
}'
After starting a batch, you will get the Batch Enrichment ID that can be used to track and download the output. Please note, this ID is different from the Batch Input ID (which is used to track the input files). Here, we get the batch enrichment ID as 45259 along with many other details.
{
"id": 45259,
"name": "email-validation-hsingh@demystdata.com-2022-10-19",
"region_id": 1,
"aegean_batch_input_id": 45991,
"batch_uuid": "d134753f-588a-425e-8016-1c39408c9b80",
"created_at": "2022-10-18T03:19:11.000Z",
"updated_at": "2022-10-18T03:19:11.000Z",
"state": "draft",
"num_rows": 2,
"aegean_batch_input": {
"id": 45991,
"name": "input_file.csv",
"region_id": 1,
"created_at": "2022-10-18T03:09:38.000Z",
"updated_at": "2022-10-18T03:09:38.000Z",
"headers": [
"email_address"
],
"num_rows": 2,
"latest_s3_object": {
"key": "batches/2ec89768-7183-1234-92a8-486961cb4716",
"bucket": "demyst-inputs-p-mt-us-east-1",
"region": "us-east-1"
}
},
"organization": {
"name": "Demyst Data",
"credit_balance": 705525817
},
"user": {
"email": "hsingh@demystdata.com"
},
"table_providers": [
{
"id": 15,
"name": "domain_from_email",
"created_at": "2017-08-23T14:05:10.000Z",
"updated_at": "2022-10-18T00:00:40.000Z",
"description": "Web domain validation and descriptive information. Sample Connector from Demyst to enable testing and integrations",
"data_region_id": 1,
"alias": "",
"product_type": "Full Release",
"is_input_file": false,
"data_category": {
"id": 4,
"name": "Digital",
"created_at": "2018-02-01T17:21:05.000Z",
"updated_at": "2019-04-30T19:50:33.000Z"
},
"aegean_data_source": {
"id": 677,
"name": "DemystData",
"website": "https://demyst.com/",
"icon": {
"url": "https://demyst-public.s3.amazonaws.com/icons/aegean_data_source/677/icon/1611613545554.jpeg"
},
"description": "Frictionless External Data",
"public_searchable": true
},
"tags": [
{
"id": 200,
"name": "Digital - Other",
"created_at": "2021-11-08T16:05:54.000Z",
"updated_at": "2021-11-17T19:06:36.000Z",
"category": "SubEntity(Data-Category)",
"description": "Anything else Digital related not relevant to other Categories"
}
]
}
]
}
If you need to replace the channel ID with individual connectors or a list of connectors, use the below although this is not recommended by Demyst.
Replace channel_id with the below and the Version ID will be available by running another GET request using the connector/provider number. This is available for each connector on the catalog
"provider_version_ids": [773]
The below request will give you provider_version_ids. Make sure to use the latest (largest ID) in the response. If you do it for 15 (domain_from_email connector, you will find the latest being 773). These extra steps can be removed by creating a Data API first
curl -X GET 'https://console.demystdata.com/table_providers/15/provider_versions' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer xxxxxx'
Tracking Batch Status using Enrich ID
You can track the status using the Batch Enrichment ID which will be 45259 in this example as we created the same from the last call above.
curl -X GET 'https://console.demystdata.com/aegean_batch_runs/45259' \
--header 'Authorization: Bearer xxxx' \
--header 'Content-Type: application/json' \
--header 'Accept: application/json'
The state in the response could be one of the following and it usually progresses in the following order
-
draft - If you set the batch to draft, it will stay in draft unless draft is set to False. This can be used to upload a file and get the batch ready and start it when the time is right
-
pending_approval - For some users, approval is needed by an admin user of the org and the batch will stay in this state unless a manual approval is given
-
uploading - The Input file uploaded to the S3 location will be uploaded to the database for (usually 20 rows at a time) for letting the batch technology that the inputs are ready to be sent to the connectors. This step takes a few seconds, sometimes depending on the input file size, but is always instantaneously
-
uploaded - Once the upload is done, it will momentarily be in the uploaded state before moving on.
-
preprocessing - In this state, the input is getting parsed and converted to upstream types for sending the request. This is also instantaneous
-
preprocessed - Same as the uploaded state, will confirm that the preprocessing is done before moving on.
-
running - This is the main state where enrichment is going on. Depending on the connector, the time could vary. Demyst hosted connectors will be faster.
-
complete - Once the enrichment is done, you will see a complete state and the output file link will be ready in this state
-
paused - You can pause your enrichment if any issues and restart, if needed.
-
error - Any access, enrichment, or input file error will be reflected through this state. You cannot go back once you are in this state but will need to make corrections and start a new batch enrichment
-
canceled - If you cancel your enrichment, you will see this state. Similar to draft, paused, and pending_approval this needs to be done manually
Downloading the Batch Output File
Once the batch enrichment state is completed, you can use the same call as above and look for the below attributes to download the output files (separated by connectors and refine). Look into batch_run_provider_versions['most_recent_export_link'] to find the pre-signed URL for downloading the files. If the URL is not working, you need to make the call again to get a new pre-signed URL. The following will apply to the URL
-
Expires in 15 minutes but can be re-generated using a call to track the status
-
The file will expire depending on the file purge setting on the platform. If this is not set, the default will be 30 days.
If you face any issues or need elevated access, reach out to your account manager or support@demystdata.com for any concerns.